9
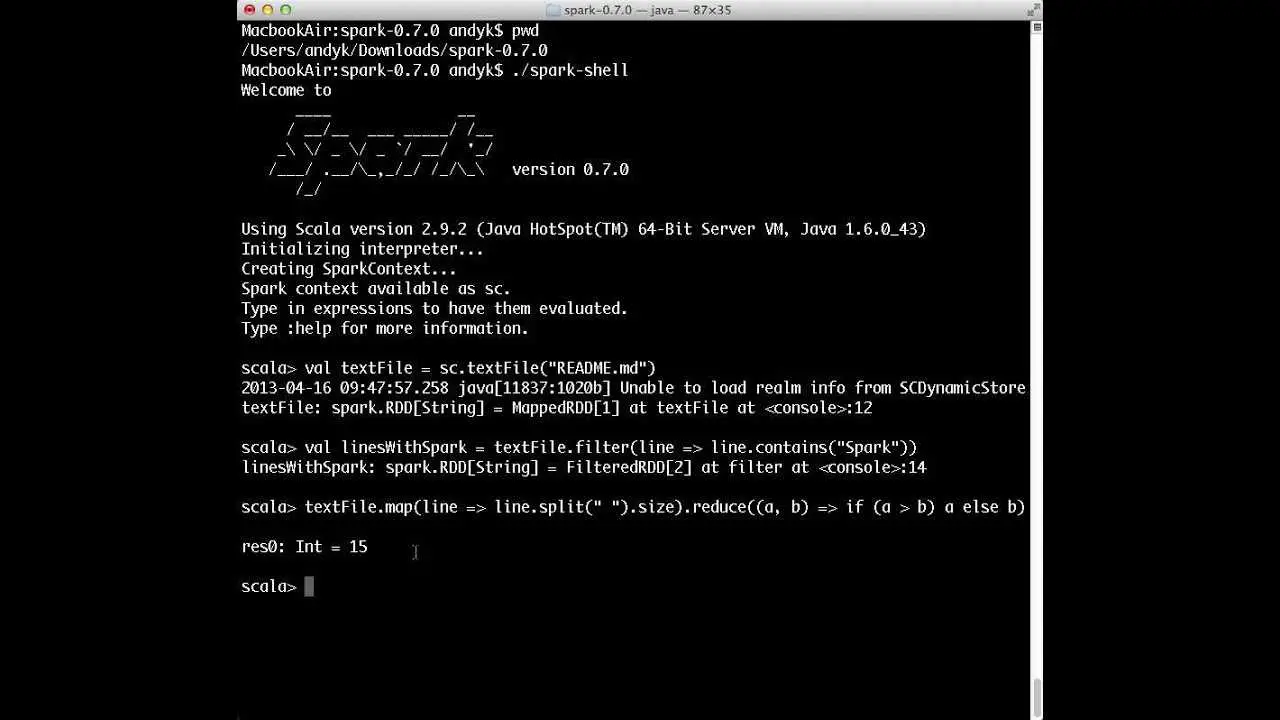
Apache Spark ™ е бърз и общ двигател за мащабна обработка на данни.Програмите за бързо изпълнение стартират до 100 пъти по-бързо от Hadoop MapReduce в паметта или 10 пъти по-бързо на диска.Spark има усъвършенстван механизъм за изпълнение на DAG, който поддържа цикличен поток на данни и изчисления в паметта.
WebSite:
http://spark.apache.orgХарактеристика
Категории