0
OCR Text Detection Tool
Осигурява точно и бързо разпознаване на текст от всеки файл с изображения, изтеглени от вашето устройство или направени с моментна снимка.Той също така поддържа текстово откриване на PDF и ръчно писане на текст и превод на текст на 114 различни езика.
- Безплатно
- Windows S
- Windows
- Windows Mobile
- Windows Phone
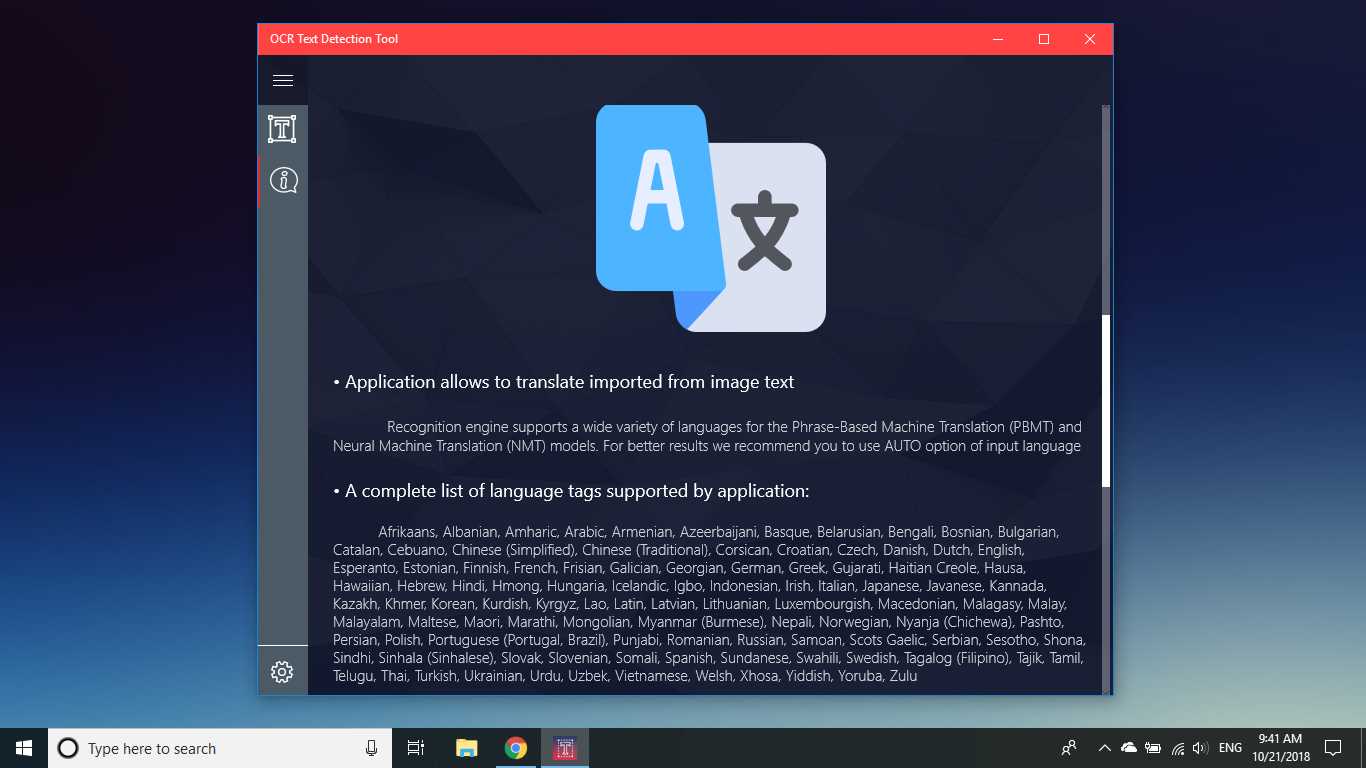
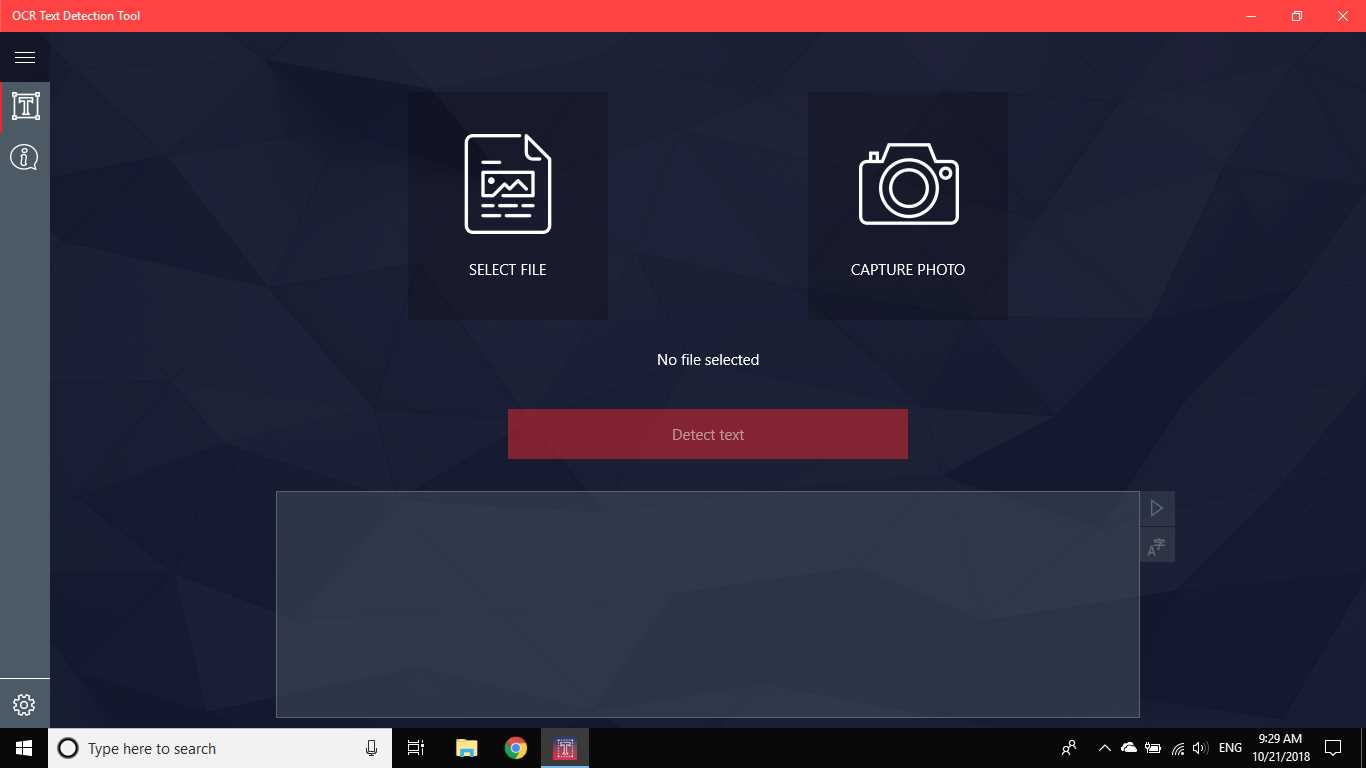
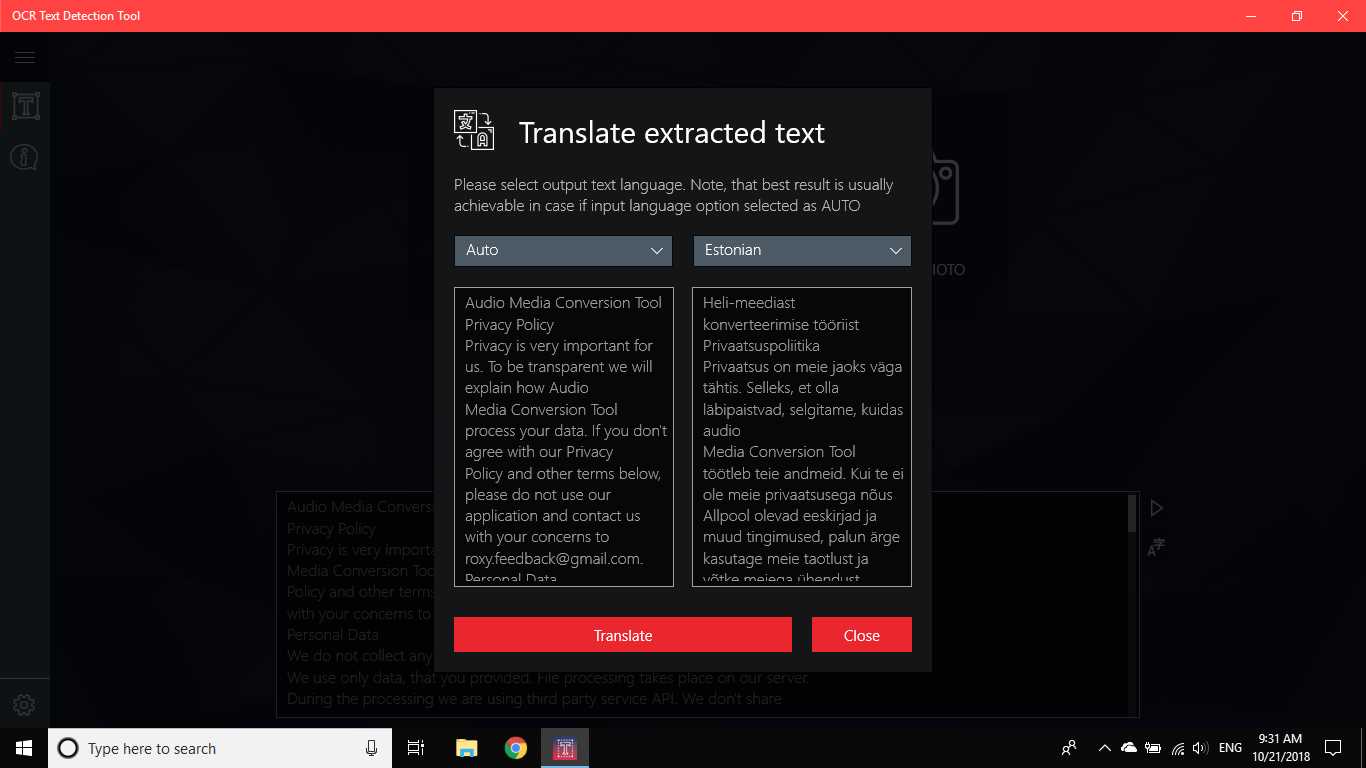
Инструмент за разпознаване на текст OCR осигурява точно и бързо откриване на текст от всеки файл с изображения, изтеглени от вашето устройство или взети с моментна снимка.Той също така поддържа текстово откриване на PDF документ (в момента не повече от 20 страници, но работим върху разширяване на функционалността).Приложението също така поддържа откриване на текст и превод на текст на 114 различни езика.Приятелният, ясен и удобен дизайн прави работата с приложението лесна и разбираема.* Налични формати: JPEG, PNG8, PNG24, GIF, анимирани GIF (само първи кадър), BMP, WEBP, RAW, ICO, TIFF, PDF (в момента не повече от 20 страници, но работим върху разширяване на функционалността) * Текстфункцията за разпознаване е в състояние да открие голямо разнообразие от езици и може да открие множество езици в рамките на едно изображение: африкаанс (af), арабски (ar), асамски (като), азербайджански (az), беларуски (be), бенгалски (bn), Български (bg), каталунски (ca), китайски (zh *), хърватски (hr), чешки (cs), датски (da), холандски (nl), английски (en), естонски (et), филипински (filили tl), финландски (fi), френски (fr), немски (de), гръцки (el), иврит (той или iw), хинди (hi), унгарски (hu), исландски (е), индонезийски (id), Италиански (то), японски (я), казахски (кк), корейски (ко), киргизски (ky), латвийски (lv), литовски (lt), македонски (mk), маратхи (mr), монголски (mn), Непалски (не), норвежки (не), пушту (ps), персийски (fa), полски (pl), португалски (pt), румънски (ro), руски (ru), санскрит (sa), сръбски (sr), Словашки (sk), словенски (sl), испански (и), шведски (sv), тамилски (ta), тайландски (th), турски (tr), украински (uk), урду (ur), узбекски (uz), виетнамски (vi) Вижте, няма какво да губите!
Характеристика
Категории
Алтернативи на OCR Text Detection Tool за Linux
71
35
GImageReader
gImageReader е обикновен Gtk / Qt преден край на Tesseract OCR Engine. Характеристики: - Импортиране на PDF документи и изображения от диск, сканиращи устройства, клипборд и екранни снимки
9
8
6
5
5
4